Cross-validation for Dimensionality Reduction
CrossValidation.RmdWhy Cross-validate Dimensionality Reduction?
When using PCA or other dimensionality reduction methods, we often face questions like:
- How many components should I keep?
- How well does my model generalize to new data?
- Which preprocessing strategy works best?
Cross-validation provides principled answers by testing how well models trained on one subset of data perform on held-out data.
Quick Example: Finding the Right Number of Components
Let’s use the iris dataset to find the optimal number of PCA components via reconstruction error.
set.seed(123)
X <- as.matrix(iris[, 1:4]) # 150 samples x 4 features
# Create 5-fold cross-validation splits
K <- 5
fold_ids <- sample(rep(1:K, length.out = nrow(X)))
folds <- lapply(1:K, function(k) list(
train = which(fold_ids != k),
test = which(fold_ids == k)
))Define the fitting and measurement functions. The measurement function projects test data, reconstructs it, and computes RMSE:
fit_pca <- function(train_data, ncomp) {
pca(train_data, ncomp = ncomp, preproc = center())
}
measure_reconstruction <- function(model, test_data) {
# Project test data to score space
scores <- project(model, test_data)
# Reconstruct: scores %*% t(loadings), then reverse centering
recon <- scores %*% t(model$v)
recon <- inverse_transform(model$preproc, recon)
# Compute RMSE
rmse <- sqrt(mean((test_data - recon)^2))
tibble::tibble(rmse = rmse)
}Now run cross-validation for 1–4 components:
results_list <- lapply(1:4, function(nc) {
cv_res <- cv_generic(
data = X,
folds = folds,
.fit_fun = fit_pca,
.measure_fun = measure_reconstruction,
fit_args = list(ncomp = nc),
backend = "serial"
)
# Extract RMSE from each fold and average
fold_rmse <- sapply(cv_res$metrics, function(m) m$rmse)
data.frame(ncomp = nc, rmse = mean(fold_rmse))
})
cv_results <- do.call(rbind, results_list)
print(cv_results)
#> ncomp rmse
#> 1 1 2.949027e-01
#> 2 2 1.603380e-01
#> 3 3 7.673558e-02
#> 4 4 5.576655e-16Two components capture most of the structure; additional components yield diminishing returns.
Understanding the Output
The cv_generic() function returns a tibble with three
columns:
- fold: The fold number (integer)
- model: The fitted model for that fold (list column)
- metrics: Performance metrics for that fold (list column of tibbles)
# Run CV once to inspect the structure
cv_example <- cv_generic(
X, folds,
.fit_fun = fit_pca,
.measure_fun = measure_reconstruction,
fit_args = list(ncomp = 2)
)
# Structure overview
str(cv_example, max.level = 1)
#> tibble [5 × 3] (S3: tbl_df/tbl/data.frame)
# Extract metrics from all folds
all_metrics <- dplyr::bind_rows(cv_example$metrics)
print(all_metrics)
#> # A tibble: 5 × 1
#> rmse
#> <dbl>
#> 1 0.157
#> 2 0.135
#> 3 0.181
#> 4 0.132
#> 5 0.197Custom Cross-validation Scenarios
Scenario 1: Comparing Preprocessing Strategies
Use cv_generic() to compare centering alone versus
z-scoring:
prep_center <- center()
prep_zscore <- colscale(center(), type = "z")
fit_with_prep <- function(train_data, ncomp, preproc) {
pca(train_data, ncomp = ncomp, preproc = preproc)
}
# Compare both strategies with 3 components
cv_center <- cv_generic(
X, folds,
.fit_fun = fit_with_prep,
.measure_fun = measure_reconstruction,
fit_args = list(ncomp = 3, preproc = prep_center)
)
cv_zscore <- cv_generic(
X, folds,
.fit_fun = fit_with_prep,
.measure_fun = measure_reconstruction,
fit_args = list(ncomp = 3, preproc = prep_zscore)
)
rmse_center <- mean(sapply(cv_center$metrics, `[[`, "rmse"))
rmse_zscore <- mean(sapply(cv_zscore$metrics, `[[`, "rmse"))
cat("Center only - RMSE:", round(rmse_center, 4), "\n")
#> Center only - RMSE: 0.0764
cat("Z-score - RMSE:", round(rmse_zscore, 4), "\n")
#> Z-score - RMSE: 0.1053For iris, centering alone performs slightly better since the variables are already on similar scales.
Scenario 2: Parallel Cross-validation
For larger datasets, run folds in parallel:
# Setup parallel backend
library(future)
plan(multisession, workers = 4)
# Run CV in parallel
cv_parallel <- cv_generic(
X,
folds = folds,
.fit_fun = fit_pca,
.measure_fun = measure_reconstruction,
fit_args = list(ncomp = 4),
backend = "future" # Use parallel backend
)
# Don't forget to reset
plan(sequential)Computing Multiple Metrics
You can return multiple metrics from the measurement function:
measure_multi <- function(model, test_data) {
scores <- project(model, test_data)
recon <- scores %*% t(model$v)
recon <- inverse_transform(model$preproc, recon)
residuals <- test_data - recon
ss_res <- sum(residuals^2)
ss_tot <- sum((test_data - mean(test_data))^2)
tibble::tibble(
rmse = sqrt(mean(residuals^2)),
mae = mean(abs(residuals)),
r2 = 1 - ss_res / ss_tot
)
}
cv_multi <- cv_generic(
X, folds,
.fit_fun = fit_pca,
.measure_fun = measure_multi,
fit_args = list(ncomp = 3)
)
all_metrics <- dplyr::bind_rows(cv_multi$metrics)
print(all_metrics)
#> # A tibble: 5 × 3
#> rmse mae r2
#> <dbl> <dbl> <dbl>
#> 1 0.0690 0.0475 0.999
#> 2 0.0603 0.0431 0.999
#> 3 0.106 0.0716 0.997
#> 4 0.0624 0.0453 0.999
#> 5 0.0863 0.0680 0.998
cat("\nMean across folds:\n")
#>
#> Mean across folds:
cat("RMSE:", round(mean(all_metrics$rmse), 4), "\n")
#> RMSE: 0.0767
cat("MAE: ", round(mean(all_metrics$mae), 4), "\n")
#> MAE: 0.0551
cat("R2: ", round(mean(all_metrics$r2), 4), "\n")
#> R2: 0.9984| Metric | Description | Interpretation |
|---|---|---|
| RMSE | Root mean squared error | Lower is better; in original units |
| MAE | Mean absolute error | Less sensitive to outliers than RMSE |
| R² | Coefficient of determination | Proportion of variance explained (1 = perfect) |
Tips for Effective Cross-validation
1. Preprocessing Inside the Loop
Always fit preprocessing parameters inside the CV loop:
# WRONG: Preprocessing outside CV leaks information
X_scaled <- scale(X) # Uses mean/sd from ALL samples including test!
cv_wrong <- cv_generic(
X_scaled,
folds,
.fit_fun = fit_pca,
.measure_fun = measure_reconstruction,
fit_args = list(ncomp = 2)
)
# RIGHT: Let the model handle preprocessing internally
# Each fold fits centering/scaling on training data only
fit_pca <- function(train_data, ncomp) {
pca(train_data, ncomp = ncomp, preproc = center())
}Advanced: Cross-validating Other Projectors
The CV framework works with any projector type. The key is writing appropriate fit and measure functions.
# Nyström approximation for kernel PCA
fit_nystrom <- function(train_data, ncomp) {
nystrom_approx(train_data, ncomp = ncomp, nlandmarks = 50, preproc = center())
}
# Kernel-space reconstruction error
measure_kernel <- function(model, test_data) {
S <- project(model, test_data)
K_hat <- S %*% t(S)
Xc <- reprocess(model, test_data)
K_true <- Xc %*% t(Xc)
tibble::tibble(kernel_rmse = sqrt(mean((K_hat - K_true)^2)))
}
cv_nystrom <- cv_generic(
X, folds,
.fit_fun = fit_nystrom,
.measure_fun = measure_kernel,
fit_args = list(ncomp = 10)
)Kernel PCA via Nyström (standard and double)
The nystrom_approx() function provides two variants:
-
method = "standard": Williams–Seeger single-stage Nyström with the usual scaling -
method = "double": Lim–Jin–Zhang two-stage Nyström (efficient whenpis large)
With a centered linear kernel and all points as landmarks
(m = N), the Nyström eigen-decomposition recovers the exact
top eigenpairs of the kernel matrix K = X_c X_c^T. Below is
a reproducible snippet that demonstrates this and shows how to project
new data.
set.seed(123)
X <- matrix(rnorm(80 * 10), 80, 10)
ncomp <- 5
# Exact setting: linear kernel + centering + m = N
fit_std <- nystrom_approx(
X, ncomp = ncomp, landmarks = 1:nrow(X), preproc = center(), method = "standard"
)
# Compare kernel eigenvalues: eig(K) vs fit_std$sdev^2
Xc <- transform(fit_std$preproc, X)
K <- Xc %*% t(Xc)
lam_K <- eigen(K, symmetric = TRUE)$values[1:ncomp]
data.frame(
component = 1:ncomp,
nystrom = sort(fit_std$sdev^2, decreasing = TRUE),
exact_K = sort(lam_K, decreasing = TRUE)
)
#> component nystrom exact_K
#> 1 1 117.64481 117.64481
#> 2 2 112.66863 112.66863
#> 3 3 103.44825 103.44825
#> 4 4 83.17891 83.17891
#> 5 5 78.30886 78.30886
# Relationship with PCA: prcomp() returns singular values / sqrt(n - 1)
p <- prcomp(Xc, center = FALSE, scale. = FALSE)
lam_from_pca <- p$sdev[1:ncomp]^2 * (nrow(X) - 1) # equals eig(K)
data.frame(
component = 1:ncomp,
from_pca = sort(lam_from_pca, decreasing = TRUE),
exact_K = sort(lam_K, decreasing = TRUE)
)
#> component from_pca exact_K
#> 1 1 117.64481 117.64481
#> 2 2 112.66863 112.66863
#> 3 3 103.44825 103.44825
#> 4 4 83.17891 83.17891
#> 5 5 78.30886 78.30886
# Out-of-sample projection for new rows
new_rows <- 1:5
scores_new <- project(fit_std, X[new_rows, , drop = FALSE])
head(scores_new)
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] -0.5065700 -0.003782324 -0.89690602 -1.2402365 -0.2466715
#> [2,] -0.3673067 0.489430969 -1.23213982 -1.5330320 0.7247966
#> [3,] 1.9065578 -0.008104080 -0.61654002 1.5191661 1.2188904
#> [4,] -1.5843734 -0.908340577 -0.94045424 -2.8897545 -2.0328659
#> [5,] 0.5690207 0.002415067 0.09988366 -0.0194067 0.5888599
# Double Nyström collapses to standard when l = m = N
fit_dbl <- nystrom_approx(
X, ncomp = ncomp, landmarks = 1:nrow(X), preproc = center(), method = "double", l = nrow(X)
)
all.equal(sort(fit_std$sdev^2, decreasing = TRUE), sort(fit_dbl$sdev^2, decreasing = TRUE))
#> [1] TRUEFor large feature counts (p >> n), set
method = "double" and choose a modest intermediate rank
l to reduce the small problem size. Provide a custom
kernel_func if you need a non-linear kernel (e.g.,
RBF).
# Example RBF kernel
gaussian_kernel <- function(A, B, sigma = 1) {
# ||a-b||^2 = ||a||^2 + ||b||^2 - 2 a·b
G <- A %*% t(B)
a2 <- rowSums(A * A)
b2 <- rowSums(B * B)
D2 <- outer(a2, b2, "+") - 2 * G
exp(-D2 / (2 * sigma^2))
}
fit_rbf <- nystrom_approx(
X, ncomp = 8, nlandmarks = 40, preproc = center(), method = "double", l = 20,
kernel_func = gaussian_kernel
)
scores_rbf <- project(fit_rbf, X[1:10, ])Numerical checks for Nyström
The exact-landmark examples above are useful sanity checks. Standard
Nyström recovers the exact centered linear kernel eigensystem when all
rows are landmarks, and double Nyström matches standard when
l = m = N.
Cross‑validated kernel RMSE: Nyström vs PCA
Below we compare PCA and Nyström (linear kernel) via a kernel‑space
RMSE on held‑out folds. For a test block with preprocessed data
X_test_c, the true kernel is
K_true = X_test_c %*% t(X_test_c). With a
rank‑k model, the approximated kernel is
K_hat = S %*% t(S), where S are the component
scores returned by project().
set.seed(202)
# PCA fit function (reuses earlier fit_pca)
fit_pca <- function(train_data, ncomp) {
pca(train_data, ncomp = ncomp, preproc = center())
}
# Nyström fit function (standard variant, linear kernel, no RSpectra needed for small data)
fit_nystrom <- function(train_data, ncomp, nlandmarks = 50) {
nystrom_approx(train_data, ncomp = ncomp, nlandmarks = nlandmarks,
preproc = center(), method = "standard", use_RSpectra = FALSE)
}
# Kernel-space RMSE metric for a test fold
measure_kernel_rmse <- function(model, test_data) {
S <- project(model, test_data)
K_hat <- S %*% t(S)
Xc <- reprocess(model, test_data)
K_true <- Xc %*% t(Xc)
tibble::tibble(kernel_rmse = sqrt(mean((K_hat - K_true)^2)))
}
# Use a local copy of iris data and local folds for this comparison
X_cv <- as.matrix(scale(iris[, 1:4]))
K <- 5
fold_ids <- sample(rep(1:K, length.out = nrow(X_cv)))
folds_cv <- lapply(1:K, function(k) list(
train = which(fold_ids != k),
test = which(fold_ids == k)
))
# Compare for k = 3 components
k_sel <- 3
cv_pca_kernel <- cv_generic(
X_cv, folds_cv,
.fit_fun = fit_pca,
.measure_fun = measure_kernel_rmse,
fit_args = list(ncomp = k_sel)
)
cv_nys_kernel <- cv_generic(
X_cv, folds_cv,
.fit_fun = fit_nystrom,
.measure_fun = measure_kernel_rmse,
fit_args = list(ncomp = k_sel, nlandmarks = 50)
)
metrics_pca <- dplyr::bind_rows(cv_pca_kernel$metrics)
metrics_nys <- dplyr::bind_rows(cv_nys_kernel$metrics)
rmse_pca <- mean(metrics_pca$kernel_rmse, na.rm = TRUE)
rmse_nys <- mean(metrics_nys$kernel_rmse, na.rm = TRUE)
cv_summary <- data.frame(
method = c("PCA", "Nyström (linear)"),
kernel_rmse = c(rmse_pca, rmse_nys)
)
print(cv_summary)
#> method kernel_rmse
#> 1 PCA 0.02153248
#> 2 Nyström (linear) 0.02266859
# Simple bar plot
ggplot(cv_summary, aes(x = method, y = kernel_rmse, fill = method)) +
geom_col(width = 0.6) +
guides(fill = "none") +
labs(title = "Cross‑validated kernel RMSE (k = 3)", y = "Kernel RMSE", x = NULL)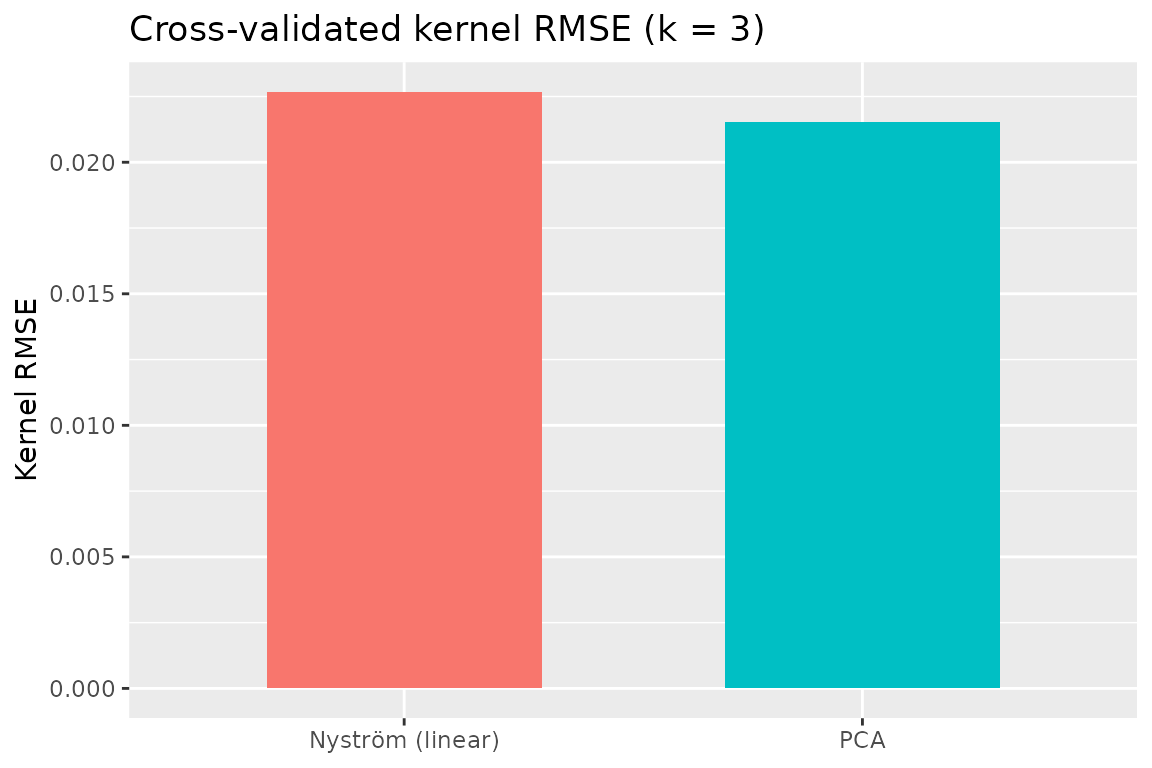
Summary
The multivarious CV framework provides: -
cross-validation for projector-like dimensionality reduction methods, -
flexible metric calculation, - parallel execution support, - tidy output
for downstream summaries.
Use it to make informed decisions about model complexity and ensure your dimensionality reduction generalizes well to new data.